DEZ Week 2 - Kestra
Table of Content
Week 1 was about SQL and 2 DevOps components that help to set the environment for a data engineering projects. In week 2, we moved on to orchestration with Kestra, a relatively new framework.
Why Orchestration?
This is a data engineering zoomcamp, so everything taught should be viewed with the perspective of a data engineer.
What data engineers do in their daily job? Most of the time it's building data pipelines which involves:
- Setting up a 24/7 server that
- runs a script at certain interval to
- take some files from one machine,
- transforming them as your colleagues wanted,
- then send them to another machine.
At the start, the volume of data is small. You can use a single on-premise server and develop the script and the environment there for all company pipelines. And to set your pipeline script to run at a set interval, a cron script suffices.
As volume of data grows while required duration to insights shortens, companies have moved their data to the cloud. Your data engineering architecture are put together from basic cloud services such as VMs or simple storage. This creates new problems such as "How to make sure production environment is always consistent?" and "How to create and destroy cloud services quickly without going through web consoles one by one?" that lead to new standards of practice (Docker and Terraform).
Similar motivation was applied to the pipelines. There may be hundreds of workflows, so we want a better UI to view them. Workflow can involve dozens of step, so we want a better language to define them. Instead of running only by schedule, we also want workflows to be triggerable by certain conditions. We want to break workflows into different steps, with the ability to checkpoint data so that it's faster to recover from failure. Adding these functionalities to cron, we now have orchestration frameworks to handle our pipelines.
To explain the concepts, I want to jump directly into the homework and use the example them.
Doing the homework with Kestra
Homework folder: https://github.com/HangenYuu/data-engineering-zoomcamp/tree/main/02-workflow-orchestration
Setting up Kestra
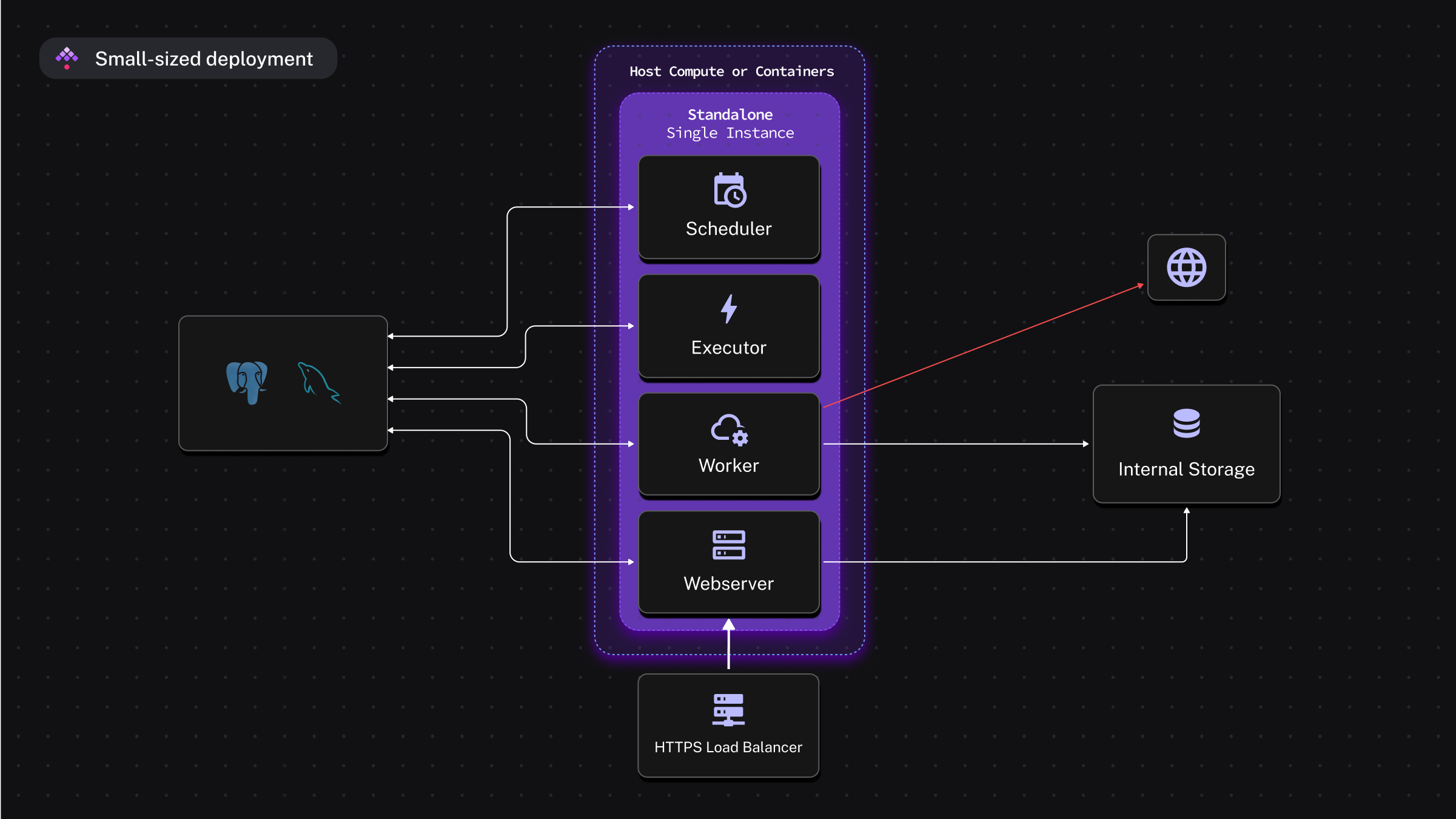
Kestra has 3 main deployment components:
- The precompiled Java application, with all internal structures defined (Scheduler, Executor, Worker, Webserver).
- JDBC SQL database to store metadata (can be PostgreSQL or MySQL).
- Internal storage to store intermediate inputs between tasks in a workflow (can be local storage, or cloud object storage service).
This can be implemented simply as 2 Docker containers for PostgreSQL and Kestra application, which is what I used for the homework (image from Kestra documentation).
Setting up Kestra was easy with the 🐳Docker Compose script provided by Kestra. To reduce storage usage on my GitHub Codespace, I only changed 2 things: deleted the volume for PostgreSQL since I won't load any data there, and set app data of Kestra to the machine /tmp/ since it's not counted to the 32GB limit of the instance 😉.
For cloud deployment:
- Deploy Kestra application on cloud Kubernetes service e.g., GCP GKE or a single cloud VM.
- Use cloud SQL service e.g., GCP CloudSQL instead of local SQL database.
- Use cloud object storage e.g., GCP GCS instead of local internal storage.
Setting up credentials
To set up and ingest data into cloud services from sources outside the cloud, we need credentials with access to the right cloud services. This includes Google Cloud Storage as data lake for raw file parking, and BigQuery as data warehouse for production data1.
States (credentials, environment variables) on Kestra will be stored on the internal KV store of the app. So the first workflow need to be set up the states in KV store.
id: 04_gcp_kv
namespace: zoomcamp
tasks:
- id: gcp_project_id
type: io.kestra.plugin.core.kv.Set
key: GCP_PROJECT_ID
kvType: STRING
value: dezoomcamp-416702
- ...
Each workflow is defined in a YAML file, identified via its namespace and id. The namespace is a logical grouping of the flows, helping to segregate secretes, environment variables, and plugins between namespaces. Each workflow has a sequence of tasks. Here, each task sets the value for one environment variables on execution2.

Setting up GCP
I set up the GCP resources with Terraform to make use of the knowledge of the first module. The resouces can also be set up with Kestra via a workflow (ifExists must be set to SKIP to not overwrite existing resource or raise errors). The workflow must be defined in the same namespace to make use of the states set up earlier.
id: 05_gcp_setup
namespace: zoomcamp
tasks:
- id: create_gcs_bucket
type: io.kestra.plugin.gcp.gcs.CreateBucket
ifExists: SKIP
storageClass: STANDARD
name: "{{kv('GCP_BUCKET_NAME')}}"
- id: create_bq_dataset
type: io.kestra.plugin.gcp.bigquery.CreateDataset
name: "{{kv('GCP_DATASET')}}"
ifExists: SKIP
pluginDefaults:
- type: io.kestra.plugin.gcp
values:
serviceAccount: "{{kv('GCP_CREDS')}}"
projectId: "{{kv('GCP_PROJECT_ID')}}"
location: "{{kv('GCP_LOCATION')}}"
bucket: "{{kv('GCP_BUCKET_NAME')}}"
The resources will be set up after successful execution (author own image).

Main workflow
The main workflow is based on the one used in the tutorial.
id: 06_gcp_taxi_scheduled
namespace: zoomcamp
description: |
Best to add a label `backfill:true` from the UI to track executions created via a backfill.
CSV data used here comes from: https://github.com/DataTalksClub/nyc-tlc-data/releases
inputs:
- id: taxi
type: SELECT
displayName: Select taxi type
values: [yellow, green]
defaults: green
variables:
file: "{{inputs.taxi}}_tripdata_{{trigger.date | date('yyyy-MM')}}.csv"
gcs_file: "gs://{{kv('GCP_BUCKET_NAME')}}/{{vars.file}}"
table: "{{kv('GCP_DATASET')}}.{{inputs.taxi}}_tripdata_{{trigger.date | date('yyyy_MM')}}"
data: "{{outputs.extract.outputFiles[inputs.taxi ~ '_tripdata_' ~ (trigger.date | date('yyyy-MM')) ~ '.csv']}}"
triggers:
- id: green_schedule
type: io.kestra.plugin.core.trigger.Schedule
cron: "0 9 1 * *"
inputs:
taxi: green
- id: yellow_schedule
type: io.kestra.plugin.core.trigger.Schedule
cron: "0 10 1 * *"
inputs:
taxi: yellow
The preamble sets up
inputs, which are variables in the flow that needs user selection at execution start.variables, which are variables in the flow that can be determined using other variables & states.triggers, which arecronconditions for the monthly pipeline in this case (triggering the workflow at the 1st of each month at 9 or 10 am). This also helps to determine the cadence during backfill. In this case, the workflow will be triggered for every month that has the 1st day in the period defined by user (e.g., Jan, Feb, and Mar 2020 for backfill period 2020-01-01 00:00:00 - 2020-03-31 23:59:59).
Next is the tasks section.
tasks:
- id: set_label
type: io.kestra.plugin.core.execution.Labels
labels:
file: "{{render(vars.file)}}"
taxi: "{{inputs.taxi}}"
- id: extract
type: io.kestra.plugin.scripts.shell.Commands
outputFiles:
- "*.csv"
taskRunner:
type: io.kestra.plugin.core.runner.Process
commands:
- wget -qO- https://github.com/DataTalksClub/nyc-tlc-data/releases/download/{{inputs.taxi}}/{{render(vars.file)}}.gz | gunzip > {{render(vars.file)}}
- id: upload_to_gcs
type: io.kestra.plugin.gcp.gcs.Upload
from: "{{render(vars.data)}}"
to: "{{render(vars.gcs_file)}}"
- id: if_yellow_taxi
type: io.kestra.plugin.core.flow.If
condition: "{{inputs.taxi == 'yellow'}}"
then:
- id: bq_yellow_tripdata
type: io.kestra.plugin.gcp.bigquery.Query
sql: ...
Workflow in orchestration framework is conceptualized as directed acyclic graphs (DAGs). The word is thrown around a lot, but it just means that you have:
- A sequence of tasks (a script, a shell command, etc.) that must be executed in one direction only.
- A task should not be executed until all dependent task have finished.
- Task dependencies do not form a loop i.e., the execution has an end.
It's quite similar to control flow graph in program execution (image from rustc-dev-guide repo of rust-lang).

In Kestra, the workflow is defined in a YAML file, with tasks defined sequentially in the tasks section. Each task in the workflow has a defined type in Kestra, which abstracts what the step does. For example, the io.kestra.plugin.gcp.gcs.Upload type in the YAML will invoke this method, which encodes the file from source, uploads it to destination in chunks of 10MB, and returns the URI for the next step. The type system also introduces programmatic elements into the workflow, such as io.kestra.plugin.core.flow.If for branching and io.kestra.plugin.core.flow.ForEach for looping.
In this case, the workflow is branched based on the condition of the input taxi, so that the CSV file is appended to the correct BigQuery table.
Doing the homework
Question 6 is not related to the data, answer can be found from this documentation.
Question 2 can also be inferred from the workflow definition.
Question 1, 3, 4, 5 require us to ingest the data of Green & Yellow taxi for year 2020, and March 2021 for Yellow taxi afterwards.
To do this, we can run backfill for the workflow in the period 2020-01-01 00:00:00 to 2020-12-31 23:59:59, assuming starting from scratch.




After running successfully (after a few trials 😅), we can see the files on GCS and the tables on BigQuery.


From GCS, we can get the answer for Question 1.
After ingesting for the whole year 2020 and before ingesting Yellow March 2021, we can get the answer for Question 3 & 4 from the "DETAILS" tab of the main table yellow_tripdata and green_tripdata.
After ingesting the Yellow March 2021, Question 5 can be read from the "DETAILS" tab for the partition yellow_tripdata_2021_03 as shown in the above picture.
Next week: Data Warehouse with BigQuery
The ETL pipeline for this week is incomplete - there's no transformation yet. So far, we have only learnt tools to set up the workflows, and partly how to extract and load data. In the next week and the workshop, we will learn more about data ingestion with dlthub, a data integration tool for Python, and BigQuery, THE cloud data warehouse from Google.
Without specification, images are own author's.