Steam Offline Recommendation System (Dev Log)
Progress: 100%.
Last edit: 9 months, 1 week ago
This is the series of my blog posts about learning and building data architecture for offline ML training of a recommendation system. This is the 1st post, detailing my development experience of the demo project.
You can read other parts here: Part 2, Part 3.
GitHub repo: https://github.com/HangenYuu/Steam-RecSys
This blog post will go through:
- Data exploration to determine required the schema.
- Data modeling & transformation to make the data more suitable for this project.
- Build the ETL data pipelines in Mage for the training data, from PostgreSQL to Google Cloud Storage.
- Build the reverse ETL data pipelines in Mage for the inference results, from Google Cloud Storage to MongoDB.
- General architecture for the next blog posts.
Data Exploration
The original data are 3 CSV files. The owner generously provided the meaning behind each column name. From it, the data type & nullability can be deduced. You can expand the element below to view it.
Detailed schema (long)
games_description.csv
| Column name | Description | Data type | Nullability | Notes |
|---|---|---|---|---|
name |
Game title | string |
non-nullable | |
short_description |
Brief description of the game | string |
nullable | Some games or DLC may have no short description |
long_description |
Detailed description of the game | string |
non-nullable | |
genres |
List of genres the game belongs to | array[string] |
non-nullable | A game can have more than 1 genre |
minimum_system_requirement |
Minimum system requirements to run the game | struct[string] |
non-nullable | Covers infrastructure parts such as OS, CPU, RAM, GPU, etc. |
recommend_system_requirement |
Recommended system requirements | struct[string] |
non-nullable | Same as above |
release_date |
Game release date | date |
non-nullable | |
developer |
Developer of the game | array[string] |
non-nullable | Same logic as genres |
publisher |
Publisher of the game | array[string] |
non-nullable | Same logic as genres |
overall_player_rating |
Overall player rating for the game | categorical |
non-nullable | |
number_of_reviews_from_purchased_people |
Number of reviews from users who purchased the game | int32 |
non-nullable | |
number_of_english_reviews |
Number of reviews written in English | int32 |
non-nullable | |
link |
URL to the game page on Steam | string |
non-nullable |
games_ranking.csv
| Column name | Description | Data type | Nullability | Notes |
|---|---|---|---|---|
game_name |
Name of the game | string |
non-nullable | |
genre |
Genre of the game | categorical |
non-nullable | Each ranking chart is for a single genre only |
rank_type |
Type of ranking (sales, revenue, or reviews) | categorical |
non-nullable | Metric for ranking, can be Sales or Revenue |
rank |
Game’s position within the ranking | uint8 |
non-nullable | The ranking is only up to position 50 |
steam_game_reviews.csv
| Column name | Description | Data type | Nullability | Notes |
|---|---|---|---|---|
review |
The content of the player’s review | string |
non-nullable | |
hours_played |
Total hours the player has spent on the game | float32 |
non-nullable | |
helpful |
Number of users who found the review helpful | int64 |
non-nullable | |
funny |
Number of users who found the review funny | int64 |
non-nullable | |
recommendation |
Whether the player recommended or did not recommend the game | boolean |
non-nullable | |
date |
Date of the review | date |
non-nullable | |
game_name |
Name of the game being reviewed | string |
non-nullable | |
username |
Username of the player who wrote the review | string |
non-nullable |
I then explored how to clean up and map the columns to the correct data type for each table. The details can be found in the notebook notebooks/1. data_exploration.ipynb in the GitHub repo.
Here are some column whose transformation are more complex and deserve highlights (based on the headache they gave me 😠)
games_description.csv
Columns"genres", "developer", "publisher" are of type array, evident from the format e.g., "['Mythology', 'Action RPG', 'Action', 'RPG', 'Souls-like']". However, there's no quick evaluation function (like eval() in Python) in Polars 🥲 i.e., no what to do option. Instead, I had to describe how to do to Polars: remove the brackets and single quotes to get "Mythology, Action RPG, Action, RPG, Souls-like", and then split it using ",".
pl.col(["developer", "publisher"])
.str.replace_many(["]", "'", "["], "")
.str.split(", ")
Column "number_of_reviews_from_purchased_people" at first glance have two formats: either a number "(654,820)" or a percentage value "(81% of 62,791) All Time". I decided to define an UDF to parse the column.
def parse_reviews(value):
if "%" in value:
# Extract percentage and total number
match = re.search(r"(\d+)% of ([\d,]+)", value)
if match:
percentage = int(match.group(1))
total = int(match.group(2).replace(",", ""))
return int((percentage / 100) * total)
else:
# Extract the number directly
match = re.search(r"\(([\d,]+)\)", value)
if match:
return int(match.group(1).replace(",", ""))
pl.col("number_of_reviews_from_purchased_people").map_elements(
parse_reviews, return_dtype=pl.Int32
)
UDF
When working with data processing framework, you want to avoid Python UDF. The speed of current frameworks depend on them making use of a compiled language like Java (Spark) or Rust (Polars). Using a Python UDF means overhead, either of data movement in/out of JVM, or of "de-parallelization" of execution (Polars documentation). Alas, I cannot find the correct operations in Polars (skill issue?). Methods to speed up UDF with NumPy or Numba also did not work for me. Ultimately, it runs fast enough, so I left it as was and moved on.
After parsing, I realized that column "number_of_reviews_from_purchased_people" has a few null values. Investigation showed that when the number of reviews is too small, the column will show "() All Time", and "overall_player_rating" will display the no. of reviews instead e.g., "1 user reviews". Since this logic is also related to converting the type of "overall_player_rating" to categorical, I separated it out as a step after specifying the data types for the above columns.
df = df.with_columns(
pl.when(pl.col("number_of_reviews_from_purchased_people").is_null())
.then(pl.lit("Not enough data"))
.otherwise(pl.col("overall_player_rating"))
.cast(pl.Categorical("lexical"))
.alias("overall_player_rating"),
pl.when(pl.col("number_of_reviews_from_purchased_people").is_null())
.then(pl.col("overall_player_rating").str.extract(r"(\d+)").cast(pl.Int32))
.otherwise(pl.col("number_of_reviews_from_purchased_people"))
.alias("number_of_reviews_from_purchased_people"),
)
steam_game_reviews.csv
Column "date" was a bigger nuisance. I found 4 different formats:
"%d %B, %Y":"12 September, 2016""%B %d, %Y":"September 12, 2016""%d %B":"28 August""%B %d":"August 28"
Investigation showed that the values with just date and month included reviews of recent games, so the year is implicitly 2024. I needed to append the year to the string, then I could parse the date with when-then-otherwise logic for each case.
df = df.with_columns(
pl.when(
~(
(pl.col("date").str.contains(r"\w+ \d{1,2},\s\d{4}"))
| pl.col("date").str.contains(r"\d{1,2} \w+,\s\d{4}")
)
)
.then(pl.concat_str([pl.col("date"), pl.lit(", " + str(datetime.now().year))]))
.otherwise(pl.col("date"))
.alias("date"),
pl.when(pl.col("username").str.contains("\n"))
.then(pl.col("username").str.extract(r"^(.*?)\n"))
.otherwise(pl.col("username").fill_null("anonymous"))
)
df = df.with_columns(
pl.when(pl.col("date").str.contains(r"\w+\s\d{1,2},\s\d{4}"))
.then(pl.col("date").str.to_date("%B %d, %Y", strict=False))
.when(pl.col("date").str.contains(r"\d{1,2}\s\w+,\s\d{4}"))
.then(pl.col("date").str.to_date("%d %B, %Y", strict=False))
)
Optimization
Here's my first logic to parse the "date" column.
def parse_date_without_year(date_str):
date_str = date_str + ", " + str(datetime.now().year)
try:
# Try "Day Month" format
return datetime.strptime(date_str, "%d %B, %Y").date()
except ValueError:
try:
# Try "Month Day" format
return datetime.strptime(date_str, "%B %d, %Y").date()
except ValueError as e:
pass
pl.when(pl.col("date").str.contains(r"\w+ \d{1,2}, \d{4}"))
.then(pl.col("date").str.to_date("%B %d, %Y", strict=False))
.when(pl.col("date").str.contains(r"\d{1,2} \w+, \d{4}"))
.then(pl.col("date").str.to_date("%d %B, %Y", strict=False))
.when(pl.col("date").str.contains(r"^(\d{1,2} \w+|\w+ \d{1,2})$"))
.then(pl.col("date").map_elements(parse_date_without_year, return_dtype=pl.Date))
.alias("date")
This is inefficient because the UDF introduces a performance bottleneck. The date parsing logic is also repeated in both the then clause and the UDF.
To improve, I realized that UDF was just for appending the current year to the date string, which could be done with Polars API. I decided to add the year to date-month only rows first, then parse the rows to date type using Polars APIs only as above. This also removed 1 when-then branch since there would be only 2 cases now, which is desirable since the checking is sequential and affects execution time. It also removed the UDF bottleneck.
The performance with and without the UDF was significant since this dataset was large. Execution time was reduced from nearly 1 minute in 2-core 8GB RAM machine to barely 1 second.
Data Modeling
Here's the entity-relationship diagram for the original data using crow's foot notation.

The data were not normalized like the way data from an operational database should look like.
3rd normal form (3NF)
In database system with online transaction processing (OLTP) access pattern, the emphasis is placed on the write transactions. The data is often normalized to reduce data redundancy to reduce the write overhead. For normalization, there are different forms, corresponding to increasing guarantee level for data non-redundancy (or data consistency in updating). However, higher normal forms fragment the data more, so more joins are required during read time, which can decrease performance. A rule of thumb for the sweet spot is the 3rd normal form (3NF).
Here're the requirements from 1NF to 3NF:
- 1NF requires that a field may not contain a set of values or a nested record.
- 2NF requires 1NF and all non-unique-identifier (UID) attributes are dependent on all UID attributes.
- 3NF requires 2NF and all non-UID attributes are only dependent on the UID attributes.
Apply 3NF's requirements to the current tables:
- Nested columns such as
genresin the Games table is violating 1NF and needs to be unnested. - User-specific and game-specific information in Reviews table is violating 2NF and needs to be separated out in Games and Users table.
- Make sure the condition of 3NF in each table.
To normalize this Reviews table, we need to
- Create a Games and a Users dimensios tables, which link to Reviews table via IDs.
- Additionally, for nested column such as
genres(array of string) in the Games, we create a bridge table e.g., Games_Genres which bridges between Games and Genres to simplify the relationship and make it easier to update.
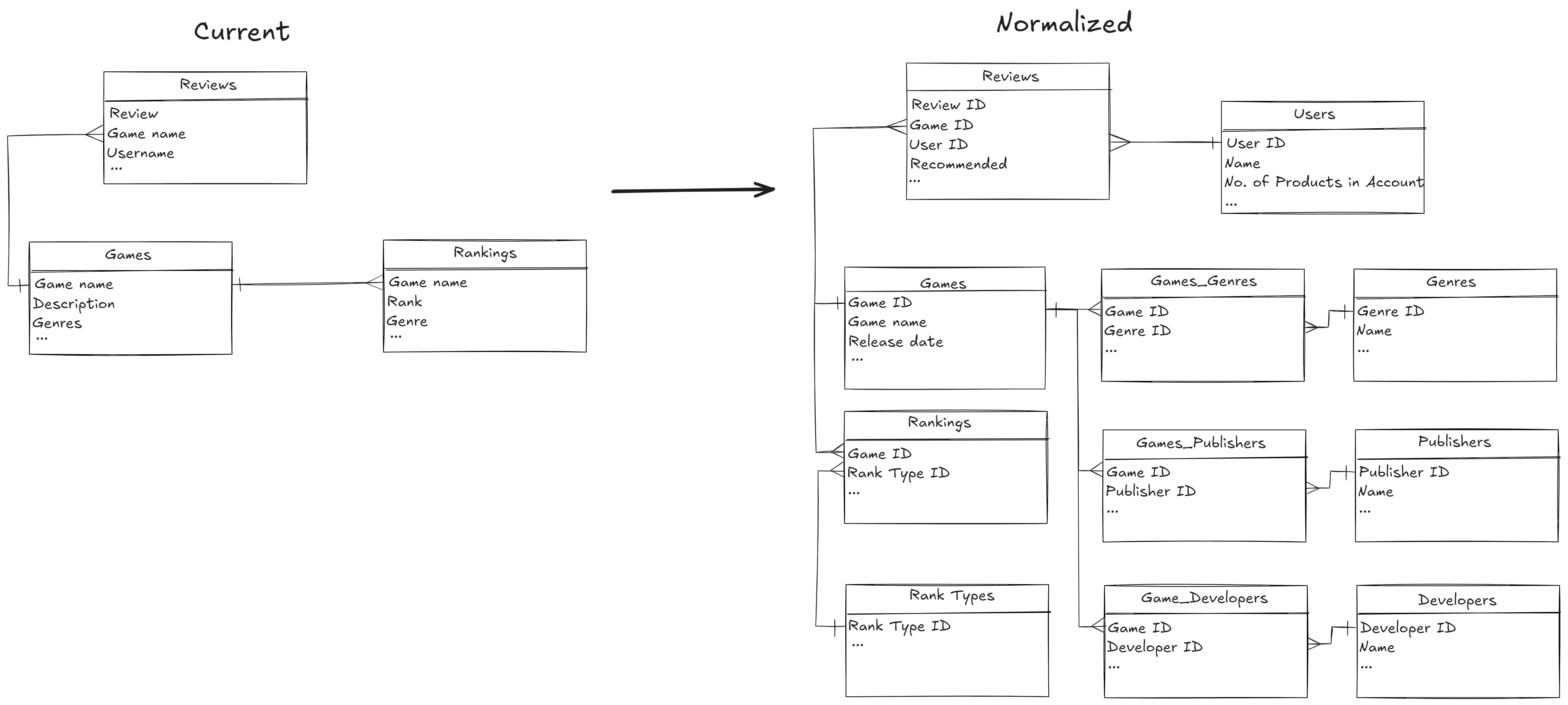
Under the new schema, the Reviews table is already ready for running collaborative filtering on.
ML Algorithm
As I explained, the focus of this project is on data engineering, so I did not do any fancy recommendation algorithm. So a Collaborative Filtering with implicit feedback algorithm was chosen.
This choice (of my hypothetical MLE colleagues) led to requirements for the Reviews table:
- Must have non-null user column (
"user_id"). - Must have non-null product column (
"game_id"). - Must have columns indicating user interactions with the product (
"recommendation"is the binary feedback).
IDs
The intention of using IDs in a database is to provide a unique, efficient, and scalable way to identify and manage records. We technically can use game name and user name as IDs but it's not a good idea:
- Non-uniqueness.
- Length and complexity mismatch even if uniqueness is enforced.
- Case sensitivity and formatting.
- Performance issue during joining of tables.
ETL pipelines
Preparation
After normalizing the original data and store them as Parquet files, I ingested them to a PostgreSQL container as are. It's the nice thing about Parquet vs plain-text format like CSV: the schema is already included in the file format, so if the schema is already correct when I save the data, they can be ingested directly into a SQL database without further specification.
Pipeline Designs
In notebooks/3. postgres_tables_check.ipynb I checked the schema of the data pulled out of the database using Polars. My observations:
- All column data types are correct except for datetime columns.
- Column with names corresponded with PostgreSQL keywords were changed (
_name,_date).
Both point 1 and 2 affected 2 tables.
Based on this observations, the data could be ingested by building 3 data pipelines:
- One generic for tables ready to be ingested as are. Take data out of SQL database, put data in GCS - simple two steps.
- Two for the two tables that need 1) datetime column cast to correct type and 2) some column renamed before ingesting. That's three steps.
Mage
Mage is a new data pipeline & orchestration tool. Like older tools such as Airflow, Mage represents the data pipelines as directed acyclic graphs (DAGs), which describe the order the scripts (in Python, SQL, or R1) should be run. Each pipeline has its own trigger to run, which can be a cron schedule, when another pipeline finishes running, or ad-hoc manner.
My experience with Mage also told me that it was not good for production2. However, I think it's a great tool for learning:
- Basic features nailed down: The most basic things you expect in a data pipeline & orchestration tool is there. Slightly more advanced stuff such as dynamic block are also included.
- Transparent & simple back-end: You can see everything Mage does behind the scene in the IDE and it's also easy to understand. I will show several screenshots in the next blog post to illustrate this.
- Annotated scripts: The scripts (called "blocks") are automatically divided into folder with purpose for each e.g., Data Loader, Transformer, Data Exporter. It's part of the low-code experience, and it's great for learning.
Why not for production?
The immaturity mostly shines through the lack of many features (visit the GitHub repo to see). One example is the documentation. I get that it's a low-code tool, so I cannot expect detailed APIs and arguments. But I came up with nothing when I tried to search for the tool design. Why Pandas only (Polars support is added in some blocks but not the other) in the blocks? Why there's no place telling me that Spark is used to pass data around in the backend (I had to encounter an error, guess what, or using Polars instead of Pandas in an unsupported block to surface a Spark error)? Why not just use PySpark and SparkR APIs in non-SQL blocks (if a data engineer can write something in Pandas and Polar, it'll be a red flag and skill issue if he cannot transfer the code to PySpark)? I can switch to using Spark executor, but does that mean I need to refactor the Pandas code to PySpark code? And how are you handling different executor backend (don't tell me by adding another layer of back and forth with Spark for horrible performance)? As a data engineer and a developer, I don't need marketing and simple how-to. Give me the comprehensive design, the APIs, the source code, everything, and I can see for myself whether you have built a good tool.
Implementations
Refer to the GitHub repo for comprehensive details. Best way is to run the container and see for yourself.
Let's use the pipeline for Reviews table to illustrate the point.
Here's the DAG for the pipeline:

As explained, each node in the DAG is a script, which you can see from the IDEs or file UI. Each script contains a function, which works on the data receives from source and send the transformed data to the next step or final source.
The most significant thing would be there are two Data Exporter, one exports data in CSV to GCS bucket raw_games_data, the other exports data in Parquet to GCS bucket conformed_games_data. I will explain why later.
Source codes (Already in the GitHub)
load_data_from_postgresql_generic.sql
-- {{ }} is Jinja template to inject environment variable
SELECT
*,
CURRENT_DATE::DATE AS record_created_dt
FROM
{{ SCHEMA_NAME }}.{{ TABLE_NAME }}
upload_reviews_to_gcs_csv.py
from mage_ai.settings.repo import get_repo_path
from mage_ai.io.config import ConfigFileLoader
from mage_ai.io.google_cloud_storage import GoogleCloudStorage
from pandas import DataFrame
from os import path
import pandas as pd
if 'data_exporter' not in globals():
from mage_ai.data_preparation.decorators import data_exporter
@data_exporter
def export_data_to_google_cloud_storage(df: DataFrame, **kwargs) -> None:
"""
Template for exporting data to a Google Cloud Storage bucket.
Specify your configuration settings in 'io_config.yaml'.
Docs: https://docs.mage.ai/design/data-loading#googlecloudstorage
"""
df.rename(columns={"_date": "date"}, inplace=True)
df["date"] = pd.to_datetime(df["date"])
config_path = path.join(get_repo_path(), 'io_config.yaml')
config_profile = 'default'
bucket_name = kwargs['RAW_BUCKET']
object_key = f'{kwargs['TABLE_NAME']}.csv'
GoogleCloudStorage.with_config(ConfigFileLoader(config_path, config_profile)).export(
df,
bucket_name,
object_key,
)
upload_reviews_to_gcs_parquet.py
from mage_ai.settings.repo import get_repo_path
from mage_ai.io.config import ConfigFileLoader
from mage_ai.io.google_cloud_storage import GoogleCloudStorage
from pandas import DataFrame
from os import path
import os
import pyarrow as pa
import pyarrow.parquet as pq
import pandas as pd
from mage_ai.data_preparation.shared.secrets import get_secret_value
if 'data_exporter' not in globals():
from mage_ai.data_preparation.decorators import data_exporter
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = get_secret_value('GOOGLE_APPLICATION_CREDENTIALS')
@data_exporter
def export_data_to_google_cloud_storage(df: DataFrame, **kwargs) -> None:
"""
Template for exporting data to a Google Cloud Storage bucket.
Specify your configuration settings in 'io_config.yaml'.
Docs: https://docs.mage.ai/design/data-loading#googlecloudstorage
"""
project_id = "solid-acrobat-440004-g5"
bucket_name = kwargs['CONFORMED_BUCKET']
table_name = kwargs['TABLE_NAME']
root_path = f"{bucket_name}/{table_name}"
df.rename(columns={"_date": "date"}, inplace=True)
df["date"] = pd.to_datetime(df["date"])
table = pa.Table.from_pandas(df)
gcs = pa.fs.GcsFileSystem()
pq.write_to_dataset(
table,
root_path=root_path,
partition_cols=["record_created_dt"],
filesystem=gcs
)
In the exported data, I included a record_created_dt with the date as ingestion day and partition by this column. This serves two different purposes:
- This is a new practice for CDC in dimension table, practiced at Lyft and other big companies that depend on the cloud. As explained in the video, it trades the cheap storage cost of a cloud data lake for engineering time for other stuff.
- For training data, it makes identifying and loading the new set of training data for model retraining faster.


Reverse ETL pipeline
The non-fancy notebook to train and infer a minimal ALS model can be found at
notebooks/4. collaborative_filtering_example.ipynb.
Here's example inference result. It can be visualized as a table with 2 columns: User ID, and the list of 10 Game IDs to recommend to each user.
| user_id (i32) | recommendations (list[struct[2]]) |
|---|---|
| 12 | [{97,0.903083}, {78,0.897507},… |
| 26 | [{285,0.900752}, {205,0.844799… |
| 27 | [{89,0.903535}, {63,0.890931},… |
| 31 | [{158,0.893835}, {127,0.874928… |
| 34 | [{89,0.891225}, {106,0.87786},… |
Suppose that the results will be served on the website UI. When users log in, they would be shown the list of these 10 games as recommendations.

This means that we need fast retrieval for the recommendation results, even with high traffic. The results will also be looked up using the user IDs in a key-value manner. Based on these reasons, a NoSQL document database is the suitable option. I chose MongoDB for the demo since the cloud option is the easiest to set up3.
Since the inference result came from Spark and stored in Parquet, the data types are okay. I only need to remove the probability for each inference result, then it's good to go.

Source codes (Already in the GitHub)
gcs_generic_data_loader.py
from mage_ai.settings.repo import get_repo_path
from mage_ai.io.config import ConfigFileLoader
from mage_ai.io.google_cloud_storage import GoogleCloudStorage
from os import path
if 'data_loader' not in globals():
from mage_ai.data_preparation.decorators import data_loader
if 'test' not in globals():
from mage_ai.data_preparation.decorators import test
@data_loader
def load_from_google_cloud_storage(*args, **kwargs):
"""
Template for loading data from a Google Cloud Storage bucket.
Specify your configuration settings in 'io_config.yaml'.
Docs: https://docs.mage.ai/design/data-loading#googlecloudstorage
"""
config_path = path.join(get_repo_path(), 'io_config.yaml')
config_profile = 'default'
bucket_name = kwargs['BUCKET_NAME']
object_key = kwargs['OBJECT_KEY']
return GoogleCloudStorage.with_config(ConfigFileLoader(config_path, config_profile)).load(
bucket_name,
object_key,
)
@test
def test_output(output, *args) -> None:
"""
Template code for testing the output of the block.
"""
assert output is not None, 'The output is undefined'
remove_probability.py
if 'transformer' not in globals():
from mage_ai.data_preparation.decorators import transformer
if 'test' not in globals():
from mage_ai.data_preparation.decorators import test
from pandas import DataFrame
import pandas as pd
@transformer
def transform(df: DataFrame, *args, **kwargs) -> DataFrame:
"""
Template code for a transformer block.
Add more parameters to this function if this block has multiple parent blocks.
There should be one parameter for each output variable from each parent block.
Args:
data: The output from the upstream parent block
args: The output from any additional upstream blocks (if applicable)
Returns:
Anything (e.g. data frame, dictionary, array, int, str, etc.)
"""
# Specify your transformation logic here
df["recommendations"] = df["recommendations"].apply(
lambda x: [item["game_id"] for item in x]
)
return df
@test
def test_output(output, *args) -> None:
"""
Template code for testing the output of the block.
"""
assert output is not None, 'The output is undefined'
mongodb_generic_exporter.py
from os import path
from pandas import DataFrame
import pandas as pd
import json
import numpy as np
from mage_ai.settings.repo import get_repo_path
from mage_ai.io.config import ConfigFileLoader
from mage_ai.io.mongodb import MongoDB
if 'data_exporter' not in globals():
from mage_ai.data_preparation.decorators import data_exporter
class CustomEncoder(json.JSONEncoder):
def default(self, obj):
if isinstance(obj, (np.int64, np.int32)):
return int(obj)
else:
return super(CustomEncoder, self).default(obj)
@data_exporter
def export_data_to_mongodb(df: DataFrame, **kwargs) -> None:
config_path = path.join(get_repo_path(), 'io_config.yaml')
config_profile = 'default'
data_dict = df.to_dict(orient="records")
data_dict_1 = json.dumps(data_dict, cls=CustomEncoder)
data_dict_final = json.loads(data_dict_1)
MongoDB.with_config(ConfigFileLoader(config_path, config_profile)).export(
data_dict_final,
collection=kwargs['COLLECTION_NAME'],
)
Ingestion into MongoDB Cloud took a very long time, probably due to the customized JSON parser to deal with numpy data type mismatch with MongoDB. After ingestion, the collection is availabe in MongoDB (MongoDB Cloud for my case).

General Architecture
How to scale up from this project?
To start, I want to discuss the general architecture for data pipelines.

A data pipeline has 5 stages:
- Capture data from internal & external sources.
- Ingest data through batch jobs or streams.
- Store in Data Lake or Data Warehouse.
- Compute analytics aggregations and/or ML features.
- Use it in dashboards, data science, and ML.
For the current problem, we are training the ML model offline, so it'll be just batch processing. Additionally, efficient ML training requires data be stored as flat file from data lake, so we won't need a relational data warehouse4.
Here's the simplified architecture diagram

Based on this diagram, we need 2 main components:
- Low-cost high-volume storage (S3, ADLS) for data lake.
- Compute engine (Spark, Trino) for batch processing.
There are other components such as
- Data connectors (dlt) or data integration platform (Airbyte) to connect and load the data from sources.
- Orchestration tools (Metaflow, Vertex AI Pipelines) to orchestrate data and ML training pipelines and the underlying hardware.
- Low-latency key-value storage (ScyllaDB, DynamoDB) and cache (Redis) for serving the inference results.
Since we are processing large amounts of data, these components should be deployable in distributed manner.
Next
This concludes the dev log. In the next 2 blog posts, I will discuss in details
- Storage and Compute, Offline Training.
- Storage and Compute, Online Inference.
SQL is often used in Data Loader only. In the backend, Mage use Spark DataFrame to pass data between the scripts, which works almost seamlessly with Pandas.↩
Reddit shares the sentiment https://tinyurl.com/magenotmature↩
Much lazier reason is MongoDB is supported out of the box for Mage (I still have to test how MongoDB Cloud can be accessed) but not Cassandra or ScyllaDB.↩
Lingos: Author James Serra (Deciphering Data Architecture) defined relational data warehouse as the traditional SQL datawarehouse e.g., Azure SQL Server, where hardware and compute are coupled. Redshift, Snowflake, and Google BigQuery are cloud data warehouse, but they are more interface, materialized over the data lake (BigQuery architecture, where the data are stored using core technology of GCS, a storage solution that is used for data lakes). A cloud data warehouse is fundamentally different from a relational data warehouse.↩