Recommendation System Storage and Compute (Offline Training)
Progress: 100%.
Last edit: 9 months ago
This is the series of my blog posts about learning and building a recommendation system. This is the 2nd post, dealing with data architecture for the offline training case.
Recap
In Part 1, I stopped at sketching the theoretical data architecture for an offline training recommendation system.

I identified 2 main components:
- Low-cost high-volume storage for data lake.
- Compute engine for batch loading & processing.
In this blog post, I want to discuss the characteristics of the two storage and compute components, using the design of industry-grade tools.
Here's the outline of the blog post
- Distributed system in general.
- Cloud object storage for data lake - Amazon S3.
- Batch processing compute - Spark.
Disclaimer
Take what I said with a pinch of salt.
Keep in mind that's I am an undergraduate student learning about the topic, not someone with 20+ years of experience.
Distributed System1
Formally, a distributed system is defined as a system of many computers a.k.a nodes trying to achieve some task together while communicating through a network.
In the data engineering world, you want to make your system distributed for2:
- Better performance: data retrieval speed depends on geographical distance since the data packet has to physically travel through your LAN and WiFi. So a node in the same city as users will serve them faster than one across the world.
- Bigger problem: you want to process/store a huge amount of data that cannot fit into a single node.
Horizontal Scaling
How did we arrive here?
Traditionally, data were stored and processed in relational data warehouses, the like of Oracle SQL Database or Microsoft SQL Server. Simply, it's a big-ass PC with much RAMs, CPU cores, and HDDs. You run out of storage, you need to add more HDDs; you cannot compute fast enough, you need to add more CPU cores and/or RAMs. This is vertically scaling, where you increase the specs of a machine.
After the dot-com boom, the amount of data a company could face increased exponentially. Vertical scaling became physically impossible/prohibitively expensive. That was when horizontal scaling, where you increased the system total specs by adding more nodes, not more hardware parts, was introduced. This fundamentally changed how data systems are designed and implemented
There were 3 aspects described in Kleppmann's book that warrants attention when describing distributed system. Reliability, or how the system tolerates faults and failures of its parts. Scalability, or how system copes with load and how can additional compute & storage be added to cope with higher load. Maintainability, or how easy it is to keep the system running, how easy it is to understand the system, and how easy it is to extend the system. In this blog post, I want to focus on reliability (I will use the term "fault-tolerance" more often) and scalability. Machine fails with use, and when you have a network of machines, the chance any one machine in your system fails any time increase proportionately. A good distributed system should tolerate such faults and failures, and keep running smoothly. For scalability, it's recognized that a system with one machine operates differently from a system with multiple machines to achieve the same performance metrics for the same task & load parameters.
Before continue, I want to quickly introduce storage-compute disaggregation. Normally, you have storage (HDDs) and compute (CPUs) in the same machine. Disaggregation means that you separate them into different machines. When the compute nodes want to access, instead of searching in local disk, it will send a request to the storage node, the storage search for the data and send back for processing. The points is, storage nodes and compute nodes serve different specialized purposes. Hence, they also have different considerations when it comes to what fault-tolerance means.

Benefits
This separation offers several benefits3:
- Different workload requirements and optimizations: Compute nodes use their CPU for data processing things - parsing queries, optimizing, hash joins, aggregation, etc. Storage nodes use CPUs for storage things - encryption, snapshots, replicas, etc. Instead of a compromised hardware stack, you can
- Independent scaling: The compute and storage now can scale independently of each other. Since the workload characteristics are different, you can also use different hardwares for new nodes to the storage/compute fleet.
- Failure decoupling: You don't lose everything when the machine goes down. You can have a hot standby compute node, ready to be added. You can provision new machine for storage fleet, and replicate the data over.
Cloud Object Storage - AWS S3
Two Buckets
I want to address a question raised in the last blog post: while there were 2 data exporters in 2 different file formats to 2 different storage buckets?
For data lake, recommended practice is having multiple layers for increasing data quality.

For ML training, the first 2 layers are of specific interest:
- Raw: Data are put in as are - images, videos, JSON, CSV, etc. This serves as an archive of ingested structured data. Unstructured and semi-structured can be used for ML already.
- Conformed: Structured and semi-structure data in different formats are converted to one format, such as Parquet.
So that's the meaning behind the 2 buckets. The CSV is kept for audit purpose, while the Parquet is the actual ML training data.
Companies usually choose a cloud service such as Amazon S3 to implement their data lake. This allows you to scale almost to the limit of the cloud provider's data centers, as long as you can pay the bill.
For details, you can consult the detailed blog post from the distinguished engineer from the Amazon S3 team explaining the architecture of S3. The same information with updates is also found in this blog post.
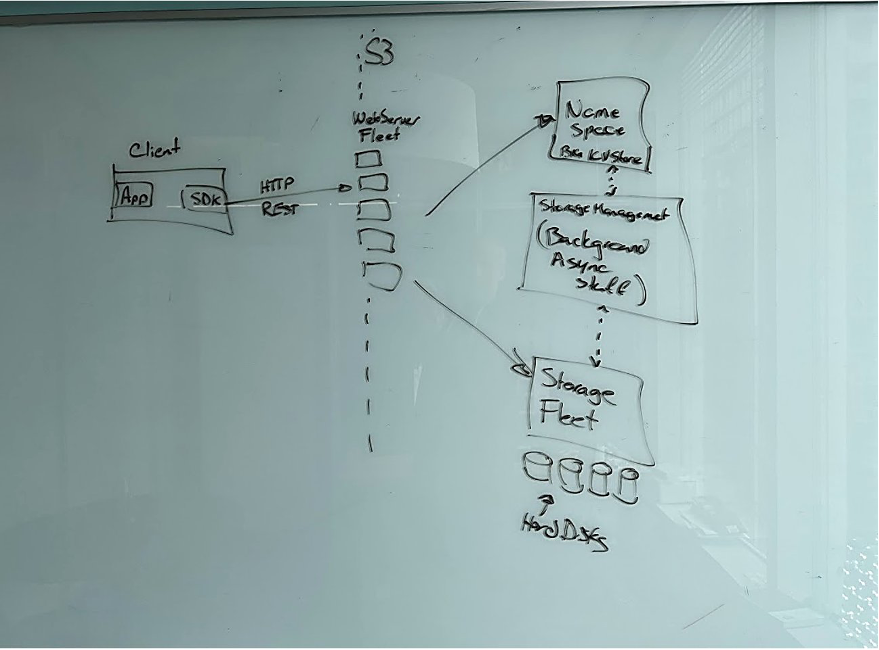
S3 reflects the movement of computing architecture to microservices with API-only communication demanded by Jeff Bezos that AWS was born from. It consists of 4 big services, each further consisting of hundreds of services, all communicating via APIs. The big 4 are:
- WebServer fleet to handle HTTP REST API from clients.
- Namespace service is a K-V store, mapping dataset name to location of its shards.
- Storage fleet of millions of HDDs, where the data live.
- Storage management fleet to perform background ops (replication to ensure durability; sharding, tiering and parallel read/write of data to ensure access speed, etc.)
In a storage system such as S3, fault-tolerance means data durability. As someone said "The question is not if S3 experiences failures (hardware, software, network, etc.). It experiences failures all the time. The question is how S3 can deliver your data even when failures happen." At the scale of S3, a storage-fleet machine failure is expected at least every hour. But they ensure an 11 9s (99.99...9%) durability, meaning only 0.000000001% of objects stored are lost annually. How do they achieve this? The high-level answer for this question is redundancy. Let's explore in 2 examples.
Example case 1: A storage node dies. S3 uses Erasure Coding, which divide the data into "identity" shards that can be used to construct the original data. There are also shards be generated, totaling maximum shards available. In this way, as long as fewer than shards become offline, the original data is still available. When one machine in the storage fleet becomes offline, the background process detects it, and replicate the lost shards to unused storage in other devices (yes, recovery happens in parallel!). Then a standby machine is provisioned and join the fleet to replace the old one.
Example case 2: Data corruption during uploading to S3 server (e.g., bit flip). To detect corruption of data after traveling in the network, the HTTP request with the data has a checksum added to its Trailer. Checksum is also added to each erasure-coded shards. During read of data, these checksums are used as fingerprints to verify data integrity. Algorithms such as CRC32C are used for fast checksum calculation
In both examples, fault-tolerance is achieved with redundancy - having back-ups or adding additional information. The redundancy principle also applies to many other fault-tolerance strategies for S3 (back-up generators for blackouts at data centers, having multiple data centers keeping copies of the data, etc.).
File Format
I want to briefly tackled the file storage format. We are working with structured data. CSV is the traditional format, and it is fine. But Parquet has become a better choice:
- Parquet has schema, so you can save pre-training data transformation by storing the data as Parquet file 🥹.
- For use case like this, while best practices call for storing the whole dataset (for audit purpose), only some columns are used for training. Parquet is a columnar storage format, so you can filter for only relevant columns to load for training. It's faster than loading the whole CSV and then dropping irrelevant columns, especially as the data size grows.
To distinguish the already trained on data from the new data, we can do data partitioning. This will physically separate the data into different directories, each for a unique value of the partitioning column (example). So in the ETL pipeline, we can specify a new column for ingestion datetime, and partition the data by it. This effectively filters new training data from old ones.
Suppose you have to build more than one model on the data e.g., build a recommendation model for each genre of game in each country. Physically partitioning the data by ingestion date, genre, and country leads to a fragmented folder structure. If now you decide to build a model for all genres and countries, the fragmented folder structure can negatively affect data loading time4 while copying the data back together is costly. In such case, we can consider storing data in an open table format built on Parquet such as Delta Lake. For such format, no physical partitioning is created, so creating the both the big model from the whole dataset and the smaller models from some parts of it is not a problem5. And with data versioning capability, it's easy to retrieve a specific version of a dataset for (re)training6.
Now I want to discuss S3's design for scalability.
On the hardware level, a read operation is a disk seek, where the HDD head searches for the on the magnetic disk. It's the bottleneck in the read operation, because IOPS of HDD has been stuck at a low level (~100s) for a long time. To deliver acceptable latency, S3 leverages parallel IO. Recall that the data are not stored as a big block, but sharded by erasure coding. These shards will be spread as broadly as possible7. When data is read out, the same number of disk seeks happen, but in parallel in many HDDs.
Shard spreading helps S3 to manage hot spot (e.g., a single request for a large amount of data on a single disk) and burst demand (e.g., sudden increase in the number of requests) effectively. In both cases, since data no longer reside in one disk, they cannot create cascading delays or bigger problems. Shard spreading also helps with heat management, since the demand on any disk is smoothed out, the heat generated is also smoothed out.
The data can also be transferred to customers in parallel from all the shards, though this is not strictly enforce, but encouraged from the client's side.
This parallel read pattern means that the write pattern needs to be parallel too. Users are encouraged to create as many parallel connections as possible. The PUT requests support multipart upload (break objects into parts and upload the parts indepedently, can be concurrently), which AWS recommends in order to maximize throughput by leveraging multiple threads. Similarly, for GET requests, each request has an HTTP header for range/part number of the object. An object can be broken into parts that are read out in parallel.
Data Archiving
Services like S3 offer different tiers of storage based on how fast you want to read the data out, with a significantly cheaper tier (S3 Glacier) for archive data that is read out around once per year. We can implement an data archiving pipeline to move the data kept for audit purpose only from the standard tier to archive tier to reduce storage cost in the long run, especially for large datasets.
Batch Processing Compute - Spark
We have the storage for our data. Now, we need compute to run our batch processing pipelines.
The first programming model for batch processing at scale is MapReduce, introduced with Apache Hadoop (image from Designing Data-Intensive Applications Chapter 10).
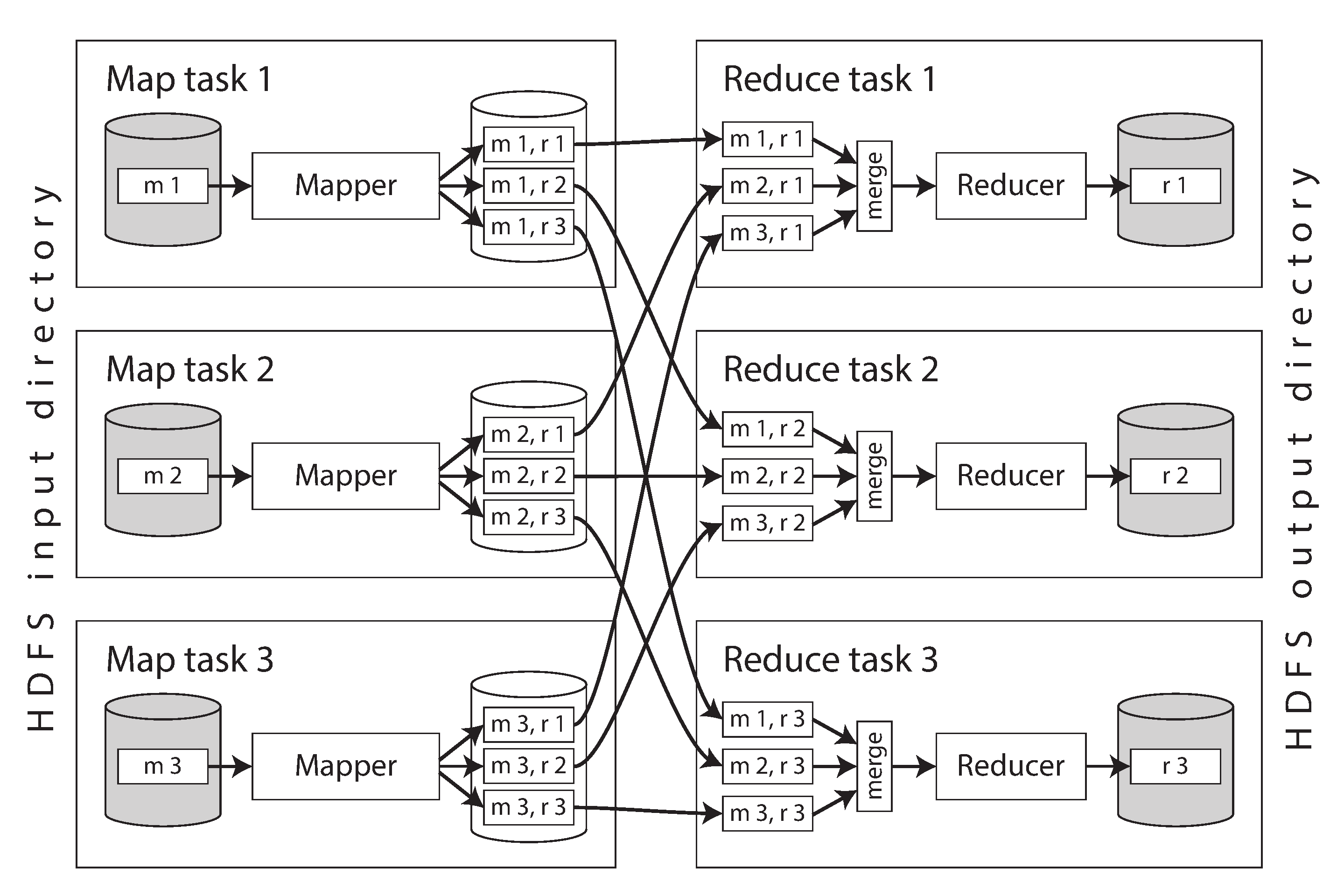
In the model, each workload is a job, each job happens in 4 tasks:
- Read a set of input records and break up into partitions. Each partition resides in one compute node.
- Call the mapper function. A mapper function will extract a key and value from each input record in a partition.
- Sort all of the key-value pairs by the hash of the key, and write the output to the disk of the mapper compute nodes.
- Call the reducer function. The reduce task takes the files from the mappers and merges them together, preserving the sort order. Thus, if different mappers produced records with the same key, they will be adjacent in the merged reducer input.
MapReduce programming model was well-designed for large-scale batch processing workloads where data flows acyclically. But this means it falls short for iterative jobs, where a working set of the data are reused across operations. Since MapReduce jobs always end with writing the dataset to disk and clear the RAM, each job on that dataset will reload the data from disk, introducing significant latency.
![[Hadoop.excalidraw.png]]
To resolve this, an idea would be keeping the data in RAM for access instead of materializing the data to disk every time. Spark was built on this premise, and have become the engine for batch-processing. Let's break it down.
The first challenge was fault-tolerance. In distributed compute, we see that each node executes a part of the processing job on a partition of the data. Fault-tolerance means that:
- The job can be finished with accurate results despite some node(s) somehow failed to do their jobs (shutdown, network disconnected, etc.).
- In the event the job has to be terminated, there are supported mechanism for fast retry.
Materializing data to disk between jobs is Hadoop's strategy - if a task fails, it can just be restarted on another machine and read the same input again. Removing this requires a different strategy for fault-tolerance when tasks fail.
![[Hadoop FT.excalidraw.png]]
Spark solution is called Resilient Distributed Datasets (RDDs), "which represents a read-only collection of objects partitioned across a set of machines that can be rebuilt if a partition is lost." RDD is used to represent the data processed and transported inside Spark. An RDD consists of 3 main elements (image from Vu Trinh):

- List of Partitions: The RDD is divided into partitions processed in different machines, which are the units of parallelism in Spark.
- Computation Function: A function determines how to compute the data for each partition.
- Dependencies: The RDD keeps track of its dependencies on other RDDs, which describes how it was created.
Functions in Spark do not modify data in-place, but return an RDD instead. A workload is a series of transformations, mapping from the input to the output, producing a lineage of RDDs as intermediates. If a partition of an RDD is lost, Spark can use this lineage to recompute the lost partition from the nearest available RDD partition in the lineage.
![[Spark FT.excalidraw.png]]
Where recomputation of data can be costly, we can checkpoint the data. It means saving the intermediate RDDs to local storage on the machine. Recomputation of RDDs' partition further down than the checkpoint in the lineage is guaranteed to happen at worse from the checkpoint instead of the beginning. It's like continuing a game from a saved point instead of the start8. This also speed up rerun in case the whole job terminates.
In most case, Spark lineage-based recovery performs better than Hadoop disk-based recovery in terms of time and resource. Today, Spark outperforms Hadoop for batch processing jobs with iterative and acyclic data flows. The performance can be attributed to minimization of , but not only that. The other reasons are:
Pipeline execution: In Hadoop, data from the previous step has to be fully written first9 before the next step can happen. In Spark, the next job can occur when the first record of the last job has arrived.
Data reuse in parallel operations: A Spark RDD can be cached in memory and used for multiple parallel operations, minimizing disk I/O (which we learnt to be slow in the above section). This can be done implicitly via Spark scheduler, or explicitly by user. In the example query, we can see that an RDD coming the Parquet source is used in 12 parallel window queries (for each month in a year), but they are in a single job, with a single read of data from disk. In Hadoop, this will be 12 different jobs, each reading the data from disk separately and levying disk I/O overhead10.

Laziness and Optimization of pipeline graph: Hadoop has a basic form of laziness, where the actual computation doesn't start until the final action is called. Spark evaluation is also lazy, but it's also optimized. On execution, Spark constructs a complete DAG of operations, then optimizes the entire chain of transformations before execution. This generally serves to combine multiple operations and eliminates unnecessary computations and data shuffles.
Conclusion & Next
This blog post attempted to capture the design choices made to storage and compute engine of a batch processing data system for offline ML training. While I tried my best to capture what I think is important, it's possible that I still missed something, due to my inexperience. I will revise the blog posts later if I realize that I have missed something.
Moving forward, there are 2 topics that I want to write up:
One, for time-sensitive use cases, while the recommendation models are trained offline, inference will become online. In such a case, a stream processing component is introduced in the system. Stream processing requires different considerations in reliability and scalability compared to batch processing. This topic is planned part 3 in the series.
Two, I mentioned in the last blog post about other components in the data architecture - data connectors, orchestration tools, low-latency K-V stores & caches, etc. These components can be present in both batch and stream processing system. They deserve their own blog post.
For this blog post, this is the end. I hope to see you again.
References
- Reis, J., & Housley, M. (2022). Fundamentals of Data Engineering (First edition). O’Reilly Media, Inc. https://www.oreilly.com/library/view/-/9781098108there298/
- Serra, J. (2024). Deciphering Data Architectures : Choosing between a Modern Data Warehouse, Data Fabric, Data Lakehouse, and Data Mesh (First edition). O’Reilly Media, Inc, 2024. https://www.oreilly.com/library/view/-/9781098150754/.
- Kleppmann, M. (2017). Designing Data-Intensive Applications : The Big Ideas behind Reliable, Scalable, and Maintainable Systems (First edition, second printing). O’Reilly Media.
- Damji, J., Lee, D., Wenig, B., Das, T., & Safari, an O’Reilly Media Company. (2020). Learning Spark, 2nd Edition (2nd edition). O’Reilly Media, Inc. https://learning.oreilly.com/library/view/learning-spark-2nd/9781492050032/
- Sadeghi, A. (2024). The History and Evolution of Open Table Formats. Medium, 2024. https://alirezasadeghi1.medium.com/the-history-and-evolution-of-open-table-formats-0f1b9ea10e1e
- Vuppalapati, M., Miron, J., Agarwal, R., Truong, D., Motivala, A., & Cruanes, T. (2020). Building an elastic query engine on disaggregated storage. In 17th USENIX Symposium on Networked Systems Design and Implementation (NSDI 20) (pp. 449-462).
- Zaharia, M., Chowdhury, M., Franklin, M. J., Shenker, S., & Stoica, I. (2010). Spark: Cluster computing with working sets. In 2nd USENIX workshop on hot topics in cloud computing (HotCloud 10).
I heavily referenced Martin Kleppmann's Designing Data-Intensive Applications book in writing this. The book was so good, I read it cover to cover before. It was also the reason why I fell in love with data systems ❤️🔥.↩
The first reason is for distributed storage, the second reason is for distributed compute.↩
Shapira, G. (2023). Compute-Storage Separation Explained. thenile.dev, 2023. Archived at https://perma.cc/QCV3-XJNZ↩
This is the small file problem discovered in Hive, which introduced physical partitioning for its table, and later in Spark.↩
In Delta Lake, there's no partitioning. Instead, the Parquet data is split into parts with non-overlapping range of value for the columns that the user specifies, instead of random parts. (As of the latest 3.x version, the feature is called liquid clustering). The whole Parquet table is still in the same folder, but the parts are constructed more mindfully.↩
OTFs like Delta Lake are essentially Parquet + transaction log, an immutable append-only log, conceptually similar to a write-ahead or commit log. The transaction log records every operation made to the table in sequential order, so tracing it backwards, we can create previous version of the data with the current data. The previous physical data in Parquet format will be stored in the same folder, but will not be listed in the transaction log as part of the current version, so they will be skipped in query. This obviously incurs redundant storage and costs. Delta Lake regularly "vacuums" the files belonged to the previous versions; reading data for a previous version will create the cleaned up files again. If our dataset is really large and experiences a large chunk of updates at a time that causes recomputation of a large part, if not all (i.e, overwrite) Parquet part files, then we need to be mindful of storage and compute. If storage cost is an issue, we need to increase Delta Lake . If compute cost of previous version is an issue, we need to decrease vacuuming frequency instead to keep the parts around longer.↩
From the 2nd blog post "They’ve shared that they have tens of thousands of customers with data stored over a million physical drives."↩
We can manually implement this e.g., writing the data to a Parquet file in a data lake directory, then read from this to continute subsequent transformations.↩
Hadoop also write to HDFS whose own replication mechanism for durability incurs additional latency.↩
This was actually something I optimized at work, using tip 7 from https://towardsdatascience.com/1-5-years-of-spark-knowledge-in-8-tips-f003c4743083. Each window query should have taken 15 minutes, the 12 queries should have taken us 3 hours. Instead, it took 30 minutes. It was a rare chance for me, but a good one.↩