Recommendation System's Storage and Compute (Online Training & Inference)
Progress: 100%.
Last edit: 7 months, 1 week ago
This is the series of my blog posts about learning and building a recommendation system. This is the 3rd post, dealing with data architecture for the online training & inference case.
Recap & Introduction
In Part 2, I discussed the characteristics of storage and compute for an offline training recommendation system, using the example of 2 industrial tools: AWS S3 and Apache Spark.
In this blog post, I want to move how inference results are generated and used. I want to focus on the case of online training & inference, when results are expected promptly with real-time features taken into account.
Background: Recommendation Problem
We have data about two types of entity: users and items, and we have data indicating each user's preference (like, not like, buy, etc.) towards some of the items. We want to predict users' preferences to items they have not seen, especially the ones they may like, so that we can recommend them to users.
One way to reason about the problem is by defining certain properties for the items, then divide them along these properties. For example, say we are dealing with different types of potato snacks, then the properties can be brand (L*ys, Pr*ngles, etc.) flavor (seaweed, sour cream, etc.), price range ($1-10, $1,000-10,000, etc.), etc. From the interaction data, we can determine for each user the types of properties they like e.g., L*ys, seaweed, packet of 50g, then find items with similar properties and recommend to them e.g., Pr*ngles, seaweed, mini-carton of 60g. Similarly, users can be divided along certain properties, and users with properties similar to each other can be recommended the same items.
But how can we quantify "similarity"? The vector space model was adopted from the field of information retrieval to answer this question. In this model, entities are represented by vectors, and their similarity is calculated with vector similarity.
A common measure is cosine similarity, which measures the cosine of the angle formed by the vector with range from -1 to 1.
- 1 means they are pointing in the same direction (most similar possible).
- 0 means they are orthogonal (not related).
- -1 means they are diametrically opposed (opposite of each other).
Adopting this model, items can be represented by vectors of the same size (called embedding). Vector similarity score can be used to determine items similar what the user likes, and the order to recommend them.
For an industrial example, let's look at Meta Instagram Explore feature. This feature need to show users content (images, videos) from people they have never viewed before. The results need to reflect the latest user's preference, which can shift drastically during a session (e.g., a new user). Below was what were shown on my brand new account1.

From what I saw, the recommendation seems to be triggered only when I request for it by clicking on 🔍 (it takes nearly 2 seconds for me). When I closed the app and open again, the same results persisted between 5-6 sessions until everything is refreshed. They results seem to be computed together with the news feed on Home page 🏠, since I tried to stay in the home page for 2 more seconds before going to Explore, then everything was already pre-loaded.
Meta's problem is coming up with 20-50 items to recommend to a user. To achieve this, they shared 2 example approaches using the embedding. For one, we use vector search feature to retrieve candidates based on user's preferences. In other words, they try to find new posts that are similar to what the users liked/shared/saved in the past, including just now.
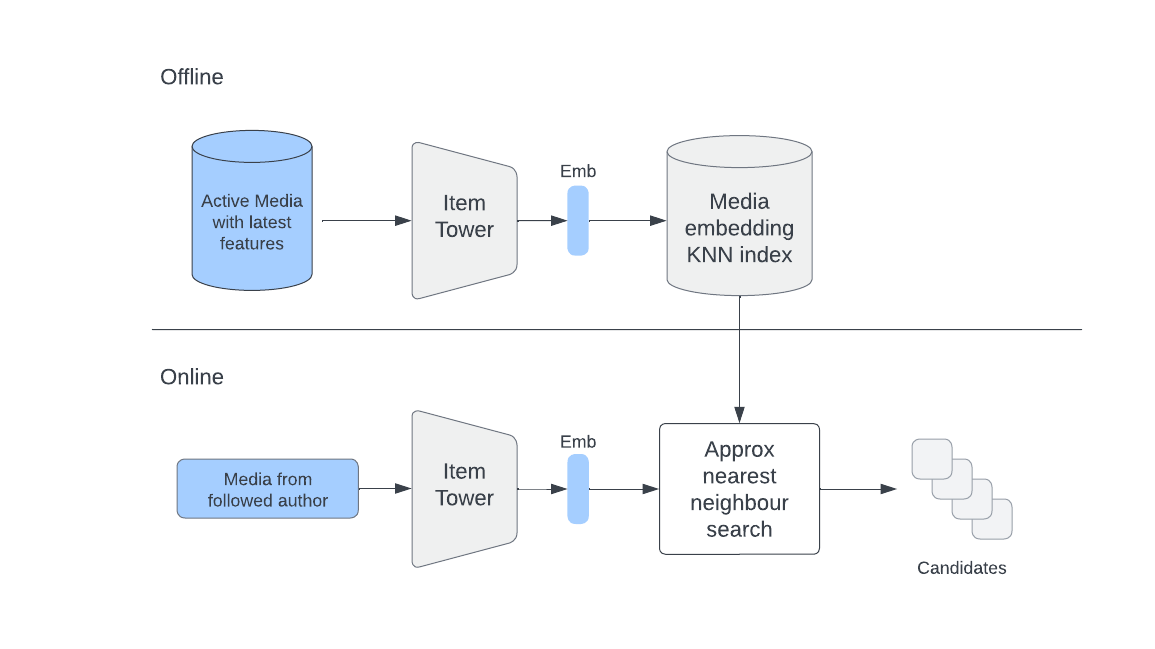
Another approach (collaborative filtering) incorporates user embeddings, where candidates are determined based on similarity to users directly. This is the Two Tower architecture, where two different embedding models are trained for user and item respectively, with the goal of producing user-item embedding pair that is similar if the user likes the item.

During online retrieval, user latest features are passed through the User Tower to create the latest embedding, which is used to retrieve relevant items.
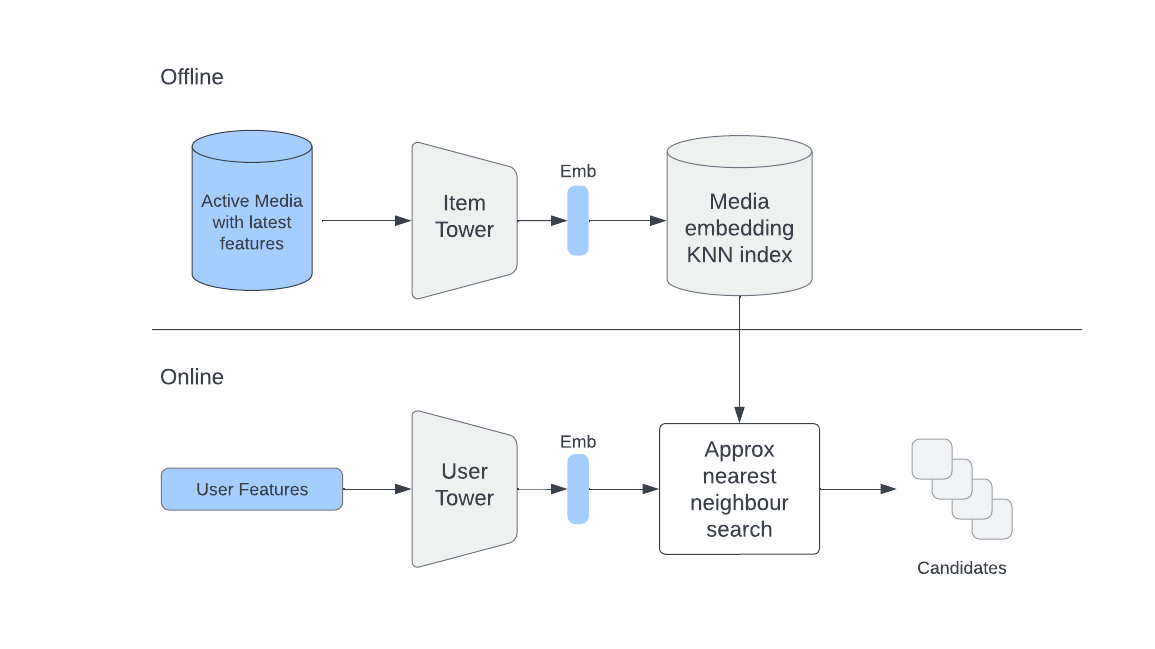
Streaming Prediction
The system for streaming prediction have two processes that happen in real-time:
- Collection of user's activities and transform them into features. This is where the blog post focuses on, particularly Kafka as a data platform. We need
- A platform for low-latency (the features can be used at the next moment) and high-throughput (a large number of users may be online at the same instance) event transport
- Compatible compute option for feature engineering directly on the stream.
- Compatible storage to store the engineered features.
- Delivery of recommendation results to user device. The gist is the results are delivered to user's devices via HTTP, with latency-reducing steps such as caching and CDNs. It's a normal web app design, so I will not dwell on them.
Streaming platform - (Apache) Kafka
The discussion for Kafka architecture, scalability, and reliability made use of the original Kafka paper plus selected LinkedIn blog posts that I came across. They were old. I will touch on the idea of Kafka as a protocol, and survey some development in Kafka-as-a-service at the end.
Apache Kafka was developed at LinkedIn for the exact purpose of "log" data analysis. This includes user activities ("logins, pageviews, clicks," etc.) and ops metrics (service call stack, call latency, CPU utilization, etc). These logs could grow order of magnitude larger than the real data of user profiles or post content. At the time, Hadoop was still and batch processing was the only viable option for data processing at this scale, so existing log transport system (such as Apache Flume that continues to exist nowdays) focused on aggregating and ingesting log data in a Hadoop warehouse. Kafka was invented with the additional API of a messaging system to enable real-time analytics on log events at LinkedIn.
The architecture was called log-based message broker. As the name suggests, each log event is treated as a message that a publisher generates and a subscriber consumes. The message is delivered by a broker, which works much like a mailman.
Physically, when publisher send messages, they are appended to a log file on broker's disk. Consumer receives message by reading the log file sequentially; if it reaches the end, it waits for new message appended. The innovation is the partitioned log. A stream of log events in the same topic is partitions into multiple parts, and each broker stores one or more of those partitions. Subscribers are not assigned individual messages, but entire partition(s) to consume sequentially.
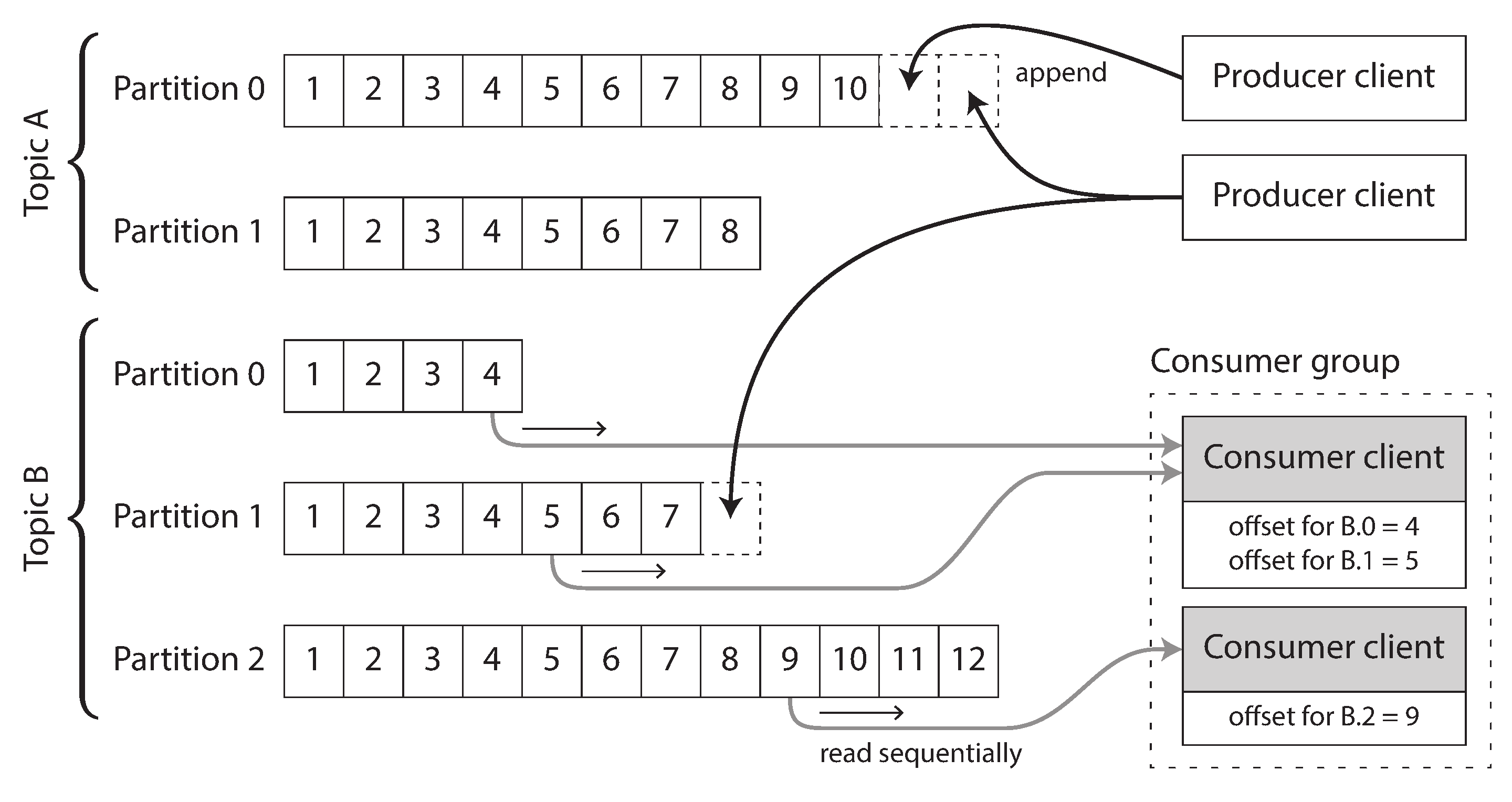
Lying at the heart of Kafka is the log, an append-only, ordered sequential record of events. It's the simplest data storage abstraction, and features in some form in all intersting software e.g., commit log of Git.
To make the log scalable, Kafka employed 3 tricks:
- Partitioned log. The log of a topic is partitioned across different broker nodes, thus consumable by multiple consumers in parallel. Events are not guaranteed to be processed in a perfect order, much like with Spark, but order is guaranteed in a partition. To achieve this, each message is assigned an offset number, which monotonically increases in a partition. This also means that broker and consumer nodes can scale horizontally and independently. New broker can be assigned partitions, and start recording from offset 1. New consumer can be assigned a new partition and starts consuming form offset 1, or from the last offset of the consumer it replaces2.
- Batching read/write. Kafka batches small reads and writes into higher-throughput operations at any step in this system. "Batching occurs from client to server when sending data, in writes to disk, in replication between servers, in data transfer to consumers, and in acknowledging committed data."
- Efficient data transfer. Typical data transfer between local file and remote socket involved (at the time) 4 data copies and 2 system calls. Kafka makes use of the Linux
sendfileAPI (underlies the JavatransferTo()method) to reduce this to 2 data copies and 1 system call. Aggregating over billions of messages, the performance gain is significant.
Moving on to reliability. Similar to Spark, partitions are replicated across a configurable number of broker nodes. Replication follows a leader-follower model3. At any time, a single node with one partition of a topic will be the leader. All writes will go to the leader, who then propagate the changes to followers. The leader with followers that have caught up with constitue the in-sync replicas. A message is acknowledged as received by broker and made availabel to consumers ("committed") when all ISRs acknowledge that it has received the message.
If a follower falls behind, it will be removed from the ISR pool until it catches up. If a follower restarts/newly joins, its log will be truncated to the last committed message, and starts receiving data from the leader to catch up.
If the leader crashes, another node will be elected to be the new leader from ISR. The election is overseen by a special "controller" broker and ZooKeeper, which manages metadata and health check (by keeping a log!).
Replication ensures fault-tolerance, but it's not fail-safe. Some message can be lost in the proces. See example below by the original paper Jun Rao at Apache Con 2013.

Kafka System Page Cache
Kafka does not explicitly caches the message, but instead relies on the file system page cache. Page cache is a portion of unused RAM that is borrowed by the OS e.g., Linux to cache disk reads and writes to avoid the expensive disk seek.
The inventors did so for 2 reasons:
- Circumvents the disadvantageous memory management of JVM, especially the high memory overhead and the slow garbage collector.
- The file system caching heuristics (write-through caching, where data is simultaneously written to disk, and read-ahead, where anticipated read requests are preloaded to cache) accommodate the sequential read pattern with a small lag between consumers and producers.
Feature engineering - Stream processing
Back to the example. User activities collected will be transported with a streaming platform like Kafka into a database, or to live processing service. For this case, we may want to perform feature engineering on the incoming activities before storing to prepare for embedding generation later.

We have many options for the stream analytics platform. Let's take a look at Spark Streaming as a representative.
The high-level abstraction for data in Spark Stream is discretized stream or DStream. Internally, a DStream is represented as a sequence of RDDs. Data is not processed one by one, but by micro-batches at regular interval e.g., 1 second (image from the documentation).

This is an opinionated design. Spark Streaming is not "real" stream processing (one-by-one record) such as Apache Flink in its default mode, but more like batch processing happening really fast. However, this design reduces overhead of small data transfer that is caused by using core Spark API, but still offer enough latency at high throughput for applications. And since the DStream is based on RDD, we have the inherent scalability of Spark. Fault-tolerance is achieved, with some tweaks which we will discuss below.
First, here is an example Spark Streaming job being run (image from Learning Spark, 2nd Edition).
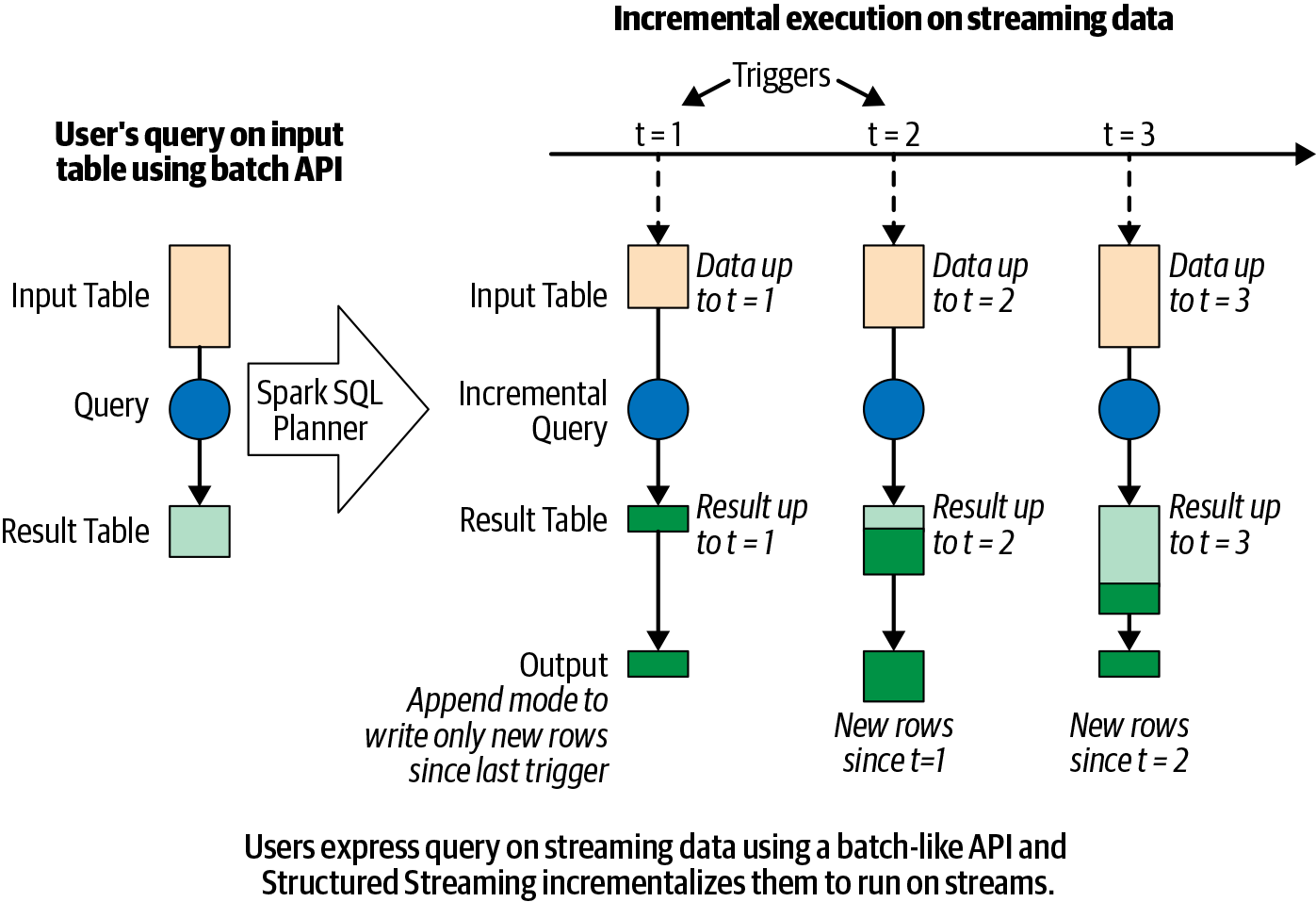
- We define the source and sink for the data, which can be Kafka producer/consumer among others.
- Spark SQL Planner constructs a logical plan and then the optimized physical plan just as with batch processing4.
- The plan is executed in a loop on each microbatch of data as they come until terminated.
- The output is incrementally written to the sink based on configuration.
The scenario for recovery from failure is a Spark node dropped amidst processing a certain batch. To recover, we need the metadata (configuration, execution plan, and range of data in incomplete batch e.g., a range of Kafka offsets) and optionally associated state (more about it later) for the new/restarted node to catch up. This is exactly what Spark does with its interval checkpointing feature. To enable it, user specifies a checkpoint directory with streamingContext.checkpoint(checkpointDirectory) method, which can be a HDFS-compatible service or RocksDB.
Exactly once guarantee
Spark Streaming can guarantee exactly once guarantee, where each input record is processed once only in the output if
- Source is replayable. An example is reading back from a smaller offset than the last offset in Kafka e.g., start from offset 5 while the last one was 30.
- Deterministic operations. This means no random number generator, or operation based on current timestamp.
- Sink is idempotent. It means that the destination can ignore duplicate writes caused by the restart.
Checkpointing is particularly useful in stateful transformations, whose result vary based on the records in the current batch or all batches of data up to now. These include grouping, joining, and aggregation such as count(). While running, the state is kept in memory and also regularly checkpointed to disk (image from Learning Spark, 2nd Edition).
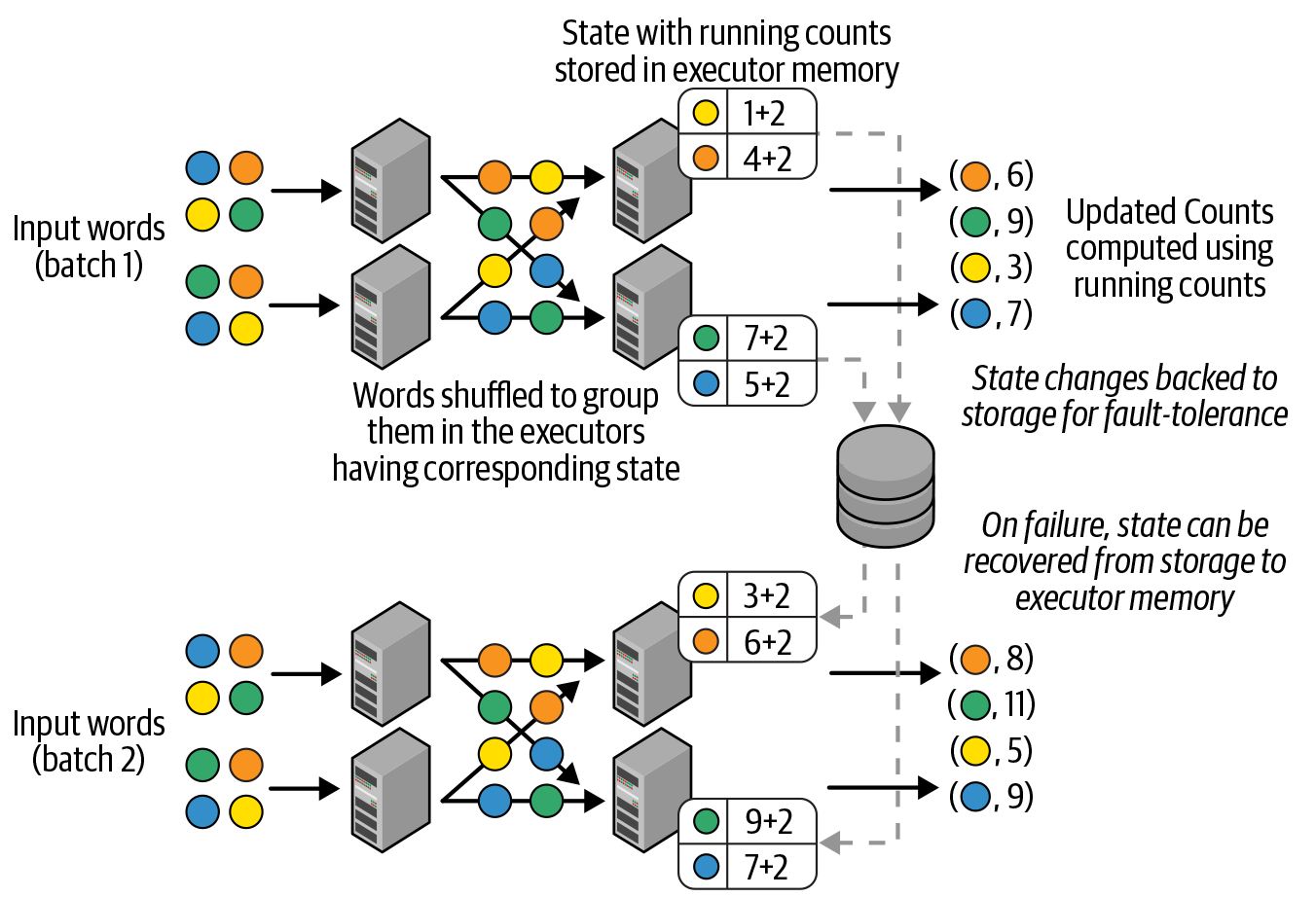
Certain stateful operations, such as nested loop join, are prohibitively expensive and are not supported by some stream processing frameworks.
In our case, the Spark Streaming application will be a Subscriber to a Kafka topic
inputDF = (spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "events")
.load())
The user activities will be processed, certain features computed (e.g., completion rate of videos, location tagging, etc.), then the data will be sinked to a destination, ready for embedding computation.
Storage - K-V database
In industrial setting, features are served from a feature store. According to definition, it seems that feature store encompasses both the compute pipeline and storage, lying between the Kafka sources and the embedding model. In practice, company often engineer their own component and create their own feature store with a stream processing engine plus a persisten i.e., disk-based K-V database. RocksDB is a popular choice, but let's use an industry example (Bilibili) instead.
Bilibili is video sharing platform quite similar to YouTube. At their size, they were dealing with terabyte-size embedding table. For their recommendation system performance, they need to implement an efficient distributed architecture for batch query5 of features. To achieve this, they built:
- A new hash table data structure NeighborHash for high query throughput with minimal memory bandwidth.
- A SSD-based distributed K-V storage based on the NeighborHash data structure that supports horizontal scaling and strong consistency of data during real-time updates.
NeighborHash is based on Coalesced Hashing, an open addressing technique for hash table where all keys are stored in a flat array. The design goal was to minimize the number of cache lines accessed during query. A cache line is the smallest unit of data transferrable between CPU cache and memory. The CPU may want 1 byte of data, but it still has to load the whole cache line (typically 64 bytes) it. As such, when we load data, we want them to reside on as few cache lines as possible. Clustering data that are aniticipated to be queried together in neighbor cache lines can save bandwidth during retrieval. NeighborHash achieved this with 2 key designs:
- Lodger relocation: They coined the concept of host and lodger. For a bucket , a host record is one with , otherwise it's a lodger. On collision, the lodger will be dislodged by the host, and moved to a close position (which is on the same or neighbor cache line) (image from the paper).

- Cacheline-aware neighbor probing: With this collision resolution strategy, buckets of the same chain likely lie on the same cache line, or at least on neighbor cache lines. During search time, bidirectional probing occurs during the cache line, then extend to its neighbors. This approach minimizes cross-cache-line probes during queries6 (image from the paper).

The NeighborHash data structure is used to store the keys in RAM. For the values, they are stored in a tiered manner, with hot data in RAM and cold data in NVMe SSD. 1 bit in the key header is used to distinguish between hot and cold data. A background thread periodically evaluates and updates hot and cold data (image from the paper).

Bilibili's Batch Query Subsystem (BQS) is responsible for retrieving the data from this storage service during online training/inference. It is architected as a multi-sharded, multi-replica framework. This helps to reduce start-up time of each instance (no one instance can get too large) and user request latency (with parallel read)7. However, this complicates data versioning. Real-time recommendation system cannot have downtime. As a full back-up for update is too expensive (essentially doubles the resources required), the team settled for rolling updates. However, this potentially introduces inconsistency in reading the data, especially for aggregated metric features.
Normally, shard and data versions are managed by the namespace service, which selects the correct ones on client's query. Latency can increase due to network delays and packet loss, which is likely between thousands of instances. To ensure performance, BQS moves shard and version metadata communication to clients and servers' interactions instead, bypassing the namespace. Shard management for is now the client's responsibility, but this reduces the network bandwidth overhead communicating through the namespace.
That's it for the interesting online components for real-time recommendation system. I want to close this with a very brief and unoriginal primer of Kafka age.
Kafka is a protocol
The idea was introduced to me through Chris Riccomini, the author of Samza at LinkedIn in his blog post. While the Kafka protocol and design took off, the Apache Kafka project did not age well. Numerous vendor have forked or re-design their own Kafka with many more features. The only thing that is still in common is the API (so that their customers can seamlessly switch). Some of the exciting names:
- AutoMQ - Kafka protocol but running entirely on cloud object storage (S3/EBS).
- WarpStream - Kafka protocol rewritten in Go. Serverless, also running entire on cloud object storage.
- Redpanda - Kafka protocol rewritten in C++. This was what used in Data Engineer Zoomcamp. Now they are also a serverless platform.
The links get you articles by Vu Trinh, who distilled pretty much anything interesting in the platform already 😅.
There are other names, of course. And they follow the same general trend. Cloud storage and compute have become so cheap that it's irresistible not to move your data and workload over there (even if it means handling over some of your privacy and security). It also means that if you can rewrite a popular but ill-suited for cloud framework from scratch with cloud-native design choices, you will have a good chance of undercutting them. And undercutting they did: WarpStream forced Confluent to acquire them, even after developing Confluent Freight to compete8.
Sorry, I don't have a closing on this matter, so I will have you hanging in there. It's time to move directly to the post conclusion.
Conclusion
This blog post continues from the last one, attempted to capture the design choices of specific components in an online recommendation system. Again, while I tried my best to capture what I think is important, it's possible that I still missed something, due to my inexperience.
It has been an exciting and looong write for this project. Moving forward, I want to continue writing. I have two venues in mind right now.
One is the Data Engineer Zoomcamp. I took it last year, but arrived late and just managed to finish the final project while skipping 3-4 modules. I want to do it properly from the beginning this year.
Second is GPU programming. I got in the GPU MODE Discord server organized by the cracked Seraphim and Aleksa. I was immediately intrigued. The people are amazing. They are solving some of the deepest problems I have seen, barring Victor Taelin and George Hotz. There are truly many amazing people out there. And I want my spot at that dinner table. So, I guess I will start getting involved with it.
Bibliography
- Kreps, J., Narkhede, N., & Rao, J. (2011, June). Kafka: A Distributed Messaging System for Log Processing. In Proceedings of the NetDB (Vol. 11, No. 2011, pp. 1-7).
- Kleppmann, M. (2017). Designing Data-Intensive Applications : The Big Ideas behind Reliable, Scalable, and Maintainable Systems (First edition, second printing). O’Reilly Media.
- Huyen, C. (2022). Designing machine learning systems. O'Reilly Media, Inc.
- Vorotilov, V., & Shugaepov, I. (2023). Scaling the Instagram explore recommendations system.
- Kreps, J. (2013) The log: What every software engineer should know about real-time data’s unifying abstraction, LinkedIn Engineering. Available at: https://engineering.linkedin.com/distributed-systems/log-what-every-software-engineer-should-know-about-real-time-datas-unifying.
- Palaniappan, S. and Nagaraja, P. (2008) Efficient data transfer through Zero copy, IBM Developer. Available at: https://web.archive.org/web/20191011141954/https://developer.ibm.com/articles/j-zerocopy/ .
- Rao, J. (2013) Intra-Cluster Replication for Apache Kafka at ApacheCon North America.
- Spark Streaming Programming - Spark 3.5.4 Documentation. Available at: https://spark.apache.org/docs/latest/streaming-programming-guide.html.
- Damji, J., Lee, D., Wenig, B., Das, T., & Safari, an O’Reilly Media Company. (2020). Learning Spark, 2nd Edition (2nd edition). O’Reilly Media, Inc. https://learning.oreilly.com/library/view/learning-spark-2nd/9781492050032/.
- Zhang, Q., Teng, Z., Wu, D., & Wang, J. (2024). An Enhanced Batch Query Architecture in Real-time Recommendation Proceedings of the 33rd ACM International Conference on Information and Knowledge Management, Boise, ID, USA. https://doi.org/10.1145/3627673.3680034
The only reason was they handed out pizza for free to those who follow the event organizer...↩
Kafka message transport follows a pull model instead of push, where the consumers asynchronously sent pull request to broker for the next buffer of messages. Since version 0.11.0.0, Kafka is transactional, which means that each message is develier exactly once, and the consumer acknowledge message in the partition it is assigned one by one. See here and here.↩
Visit Chapter 5 of Designing Data-Intensive Applications for a review of what could go wrong with replication.↩
The optimization process is less effective for Streaming, relying more on the user to do the right thing.↩
Even for recommendation of a single user, the system still has to filter candidates from thousands to millions of content uploaded recently, which is essentially a batch query. In practice, with thousands or even millions of users requesting service at an instance, batching the requests together should achieve better throughput and even latency. Any case, it's still a batch query.↩
I am not the best C++ programmer, but looking into the official implementation for their probing algorithm, it seems that they just released the linear probing implementation only.↩
Remarkably similar to Amazon S3.↩
https://materializedview.io/p/infrastructure-vendors-are-in-a-tough↩